 Potential key epigenetic players in COVID-19 infection
Potential key epigenetic players in COVID-19 infection
Resumen
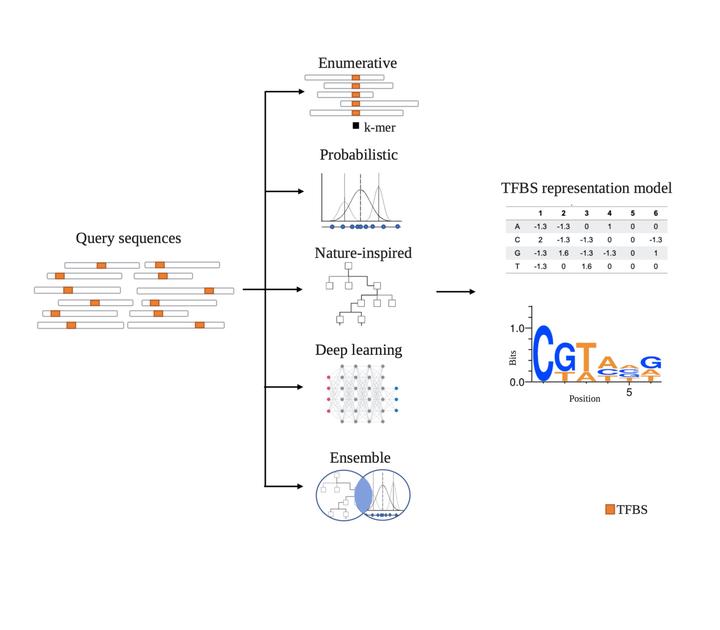
Transcription Factors (TFs) are crucial proteins that regulate gene expression in the cell. They bind to regulatory sequences and promote the transcription of genomic elements. The identification of TFs binding sites is often the first step towards a detailed understanding of their function, which has important implications to comprehend the cell, its development and differentiation. This chapter focuses on the bioinformatic analyses used to identify specific TF binding sites. It introduces the different high-throughput experimental techniques currently used to elucidate the regulatory elements such as, ChIP-seq, SELEX-seq, ChIP-on-chip, CUT&RUN or CUT&Tag, and the computational methods used to identify and/or predict the regulatory sequences targeted by TFs. The topics described here are the different TF binding motif representations, from Position Weight Matrices to Transcription Factor Flexible Models; the de novo motif discovery approaches, including the enumerative, probabilistic, nature-inspired, deep learning and ensemble algorithms; and motif prediction methods, which can consider phylogenetic foot printing or co-expression data, among others. An overview of the different tools used and their pros and cons in practice is discussed in order to understand the general workflow of TFBS studies and their experimental basis, both necessary to identify the limitations of the field.